
Llevo tiempo queriendo escribir este tipo de contenido en mi blog, pero siempre por una razón o por otra nunca lo hago, y para que negarlo, en mi cabeza todo se ve muy bonito y ordenado pero cuando intento plasmarlo en texto soy un completo desastre. Se me da fatal escribir. ?
Normalmente, cuando hacemos un buen estudio de palabras clave, suelen salirnos listados infernales que suelen contener miles, si no cientos, de palabras clave a filtrar para posteriormente analizar que suelen desmoralizar y desmotivar a cualquiera. Yo es una de las fases que mas odio y seguro que tu también, ¿o no?
En este articulo quiero contaros como limpio duplicados, agrupo términos derivados calculando las raíces semánticas de cada palabra clave para posteriormente agruparlos y eliminar de esta forma miles de keywords, como detecto las intenciones de búsqueda, que tanto están de moda ahora, y por ultimo, como detecto si el termino de búsqueda hace mención a alguna ubicación geográfica. Todo esto en un par de minutos, y de forma automática. ¿A que suena bien? ¡¡Pues vamos al lío!!
Índice de contenidos
Primeros pasos
No voy a volver a explicar aquí como instalar python en tu ordenador o hacer un keyword research o estudio de palabras clave que esta explicado en la red hasta la saciedad, y no por nada, si no porque estoy seguro que no voy a ser capaz de explicarlo mejor.
Así que lo mejor es que te ponga unos enlaces y le eches un ojo para poder continuar si no sabes como realizar estos primeros pasos, pero asumo que si estas aquí es porque ya tienes un cierto nivel y te has encontrado en mas de una ocasión con la misma problemática que yo.
Instalar Python
Lo primero que necesitaras es tener instalado python en tu ordenador. Para esto lo mejor es que sigas los pasos que puedes encontrar aquí ya que te guiaran en como instalarlo para cualquier sistema operativo.
Descargarte mi script
Después de desarrollar mi metodología de trabajo en esta tarea y ver la cantidad de horas y días que puede llevar el trabajar un listado de keywords, desarrolle un script para automatizar y reducir a unos pocos minutos lo que de otra forma me lleva días.
Tengo dos versiones diferentes que veremos mas adelante para qué y como uso cada una de ellas.
Hacer un estudio de palabras clave
En internet hay mucho escrito sobre como hacer un estudio de palabras clave, así que como he dicho anteriormente, en este aspecto no voy a reinventar la rueda. Puedes consultar este vídeo de Chuiso o si quieres una formación mas completa y de mas nivel puedes entrar en TeamPlatino.
También puede buscar en google “Como hacer un keyword research” y te van a salir miles de resultados.
Como limpiar, agrupar y detectar intenciones de búsqueda en un keyword research con Python
Cuando realizas un estudio de palabras clave, yo lo divido en 3 fases:
- Investigación
- Filtrado
- Clasificación o etiquetado
Aquí te voy a explicar como agilizar y automatizar en gran medida los puntos dos y tres, con los scripts en Python que he desarrollado.
¿Como funciona el script?
Lo primero que suelo hacer cuando hago un estudio de palabras clave, es dirigirme a Ahref con una serie de palabras clave semilla y descargar todas las sugerencias que me ofrece la herramienta.
Este proceso me genera muchos archivos csv diferentes que de forma normal tendría que ir unificando en uno solo para trabajarlo de forma mas cómoda.
Después busco plurales y singulares de la misma palabra, masculinos y femeninos, cambio de orden de las palabras que componen el termino de búsqueda y las con todas ellas genero un grupo al que llamo igual que la palabra clave que mas volumen de búsquedas tiene dentro de este grupo.
Esto puede resultar algo complicado de entender pero voy a mostrar un ejemplo.
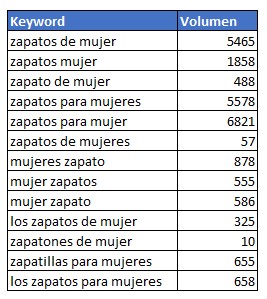
Imagina que realizas un estudio de palabras clave sobre “zapatos” y que entre los miles y miles de palabras clave identificas muchas keywords que son prácticamente idénticas y que realmente su intención de búsqueda es la misma, buscar “zapatos para mujer”. Pues bien, si esto quisiéramos limpiarlo a mano, para cada uno de los miles de términos que aparecen, nos llevaría horas. ¿Como resuelvo esto con el script en segundos?
Lo que hago es calcular para cada palabra clave su raíz semántica o lexema, de esta forma nos elimina las partes variables de la palabra y las stops words quedando una parte fija y común, por ejemplo: Para “zapatos”, “zapato” y “zapatones” la parte fija seria “zapato”. Una vez comprobadas todas las raíces semánticas de todo el listado, se comprueba que palabras clave comparten la misma raíz semántica y cual de estas palabras clave tienen mas búsquedas. De esta forma localizamos la palabra clave principal que sera la que pongamos como titulo en el grupo. Una vez procesada esta parte la tabla anterior quedaría así:
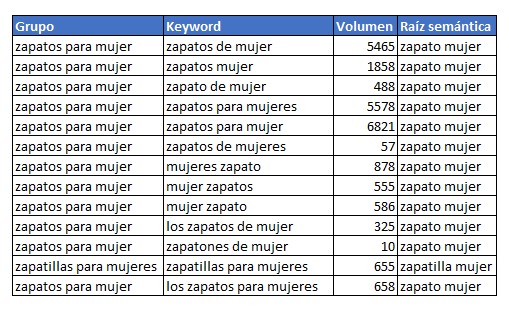
Si te fijas hemos reducido un listado de 13 palabras clave a solo 2 en el que hemos puesto como valor en la columna “Grupo” la keyword con mas búsqueda dentro de cada raíz semántica.
¿Se entiendo así algo mejor? Ya te dije que era malo explicándome por escrito.
Lo siguiente que hago es agrupar y sumar volúmenes de búsqueda de todas las keywords derivadas quedando algo así:
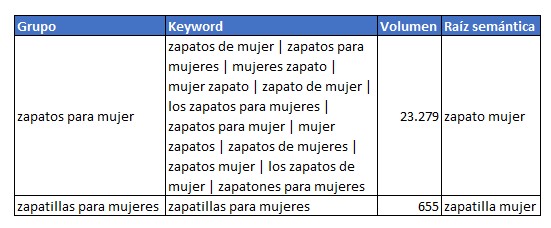
De esta forma tenemos una keyword principal (“Grupo”) que resulta mucho mas fácil clasificar y mapear con las urls de nuestra web y todas sus derivadas (“Keywords”) que vienen genial para saber que otros términos mencionar a la hora de redactar nuestro contenido.
Continuemos. Una vez llegado a este punto lo siguiente es identificar la intención de búsqueda y ubicaciones geográficas. Esto se realiza contrastando los terminos introducidos en en dos archivos csv que se encuentra en la carpeta “Data”, “ubicaciones.csv” para incluir todas las localidades, provincias, países o lugares que queramos detectar y “intenciones.csv” para incluir los términos que identifican las diferentes intenciones de búsqueda.
Yo tengo en cuenta tres intenciones de búsqueda diferentes, informacionales, navegacionales y transaccionales.
- Informacionales: Todas aquellas en las que el usuario este buscando resolver una pregunta (qué, cómo, por qué, cuando, donde…).
- Navegacionales: Todas aquellas en las que el usuario esta buscando un producto o servicio (zapatos rojos, zapatos de mujer, portátil asus…)
- Transaccionales: Todas aquellas que identifican una intención de compra o contratación (comprar, oferta, barato, precio…)
[su_note note_color=”#feffd4″] Si te interesa este tema dímelo en los comentarios y haré un articulo mas amplio sobre esto.[/su_note]
Así pues, una vez procesada esta parte, nuestra tabla quedaría de la siguiente forma:
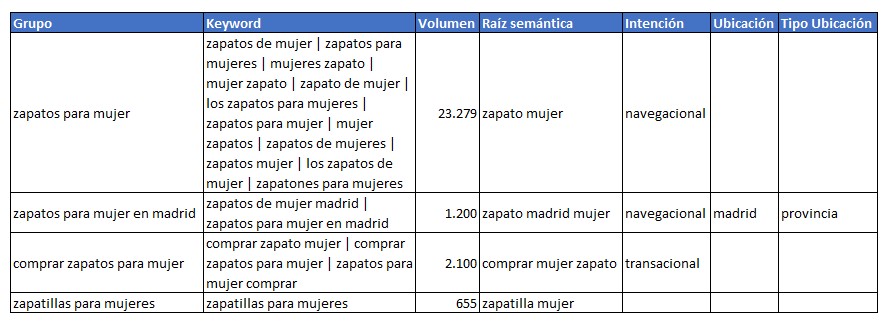
Y ya lo tendríamos muy fácil y nos habrá ahorrado horas o días de trabajo.
Script 1: Para listados de palabras clave
Este script suelo utilizarlo cuando me descargo directamente listados de palabras clave desde herramientas como Ahref o cualquier otra que te exportar listados de palabras clave a partir de una o varios términos semilla.
Los únicos requisitos que deben de cumplir los archivos es que tienen que ser .csv, estar codificados en UTF-8 y tener unas columnas concretas, ya que suelo utilizarlo con listados Ahref. Si no has sacado tu listado con esta herramienta, tendrás que adaptarlo.
- Keyword: Esta columna es donde deben estar todos los términos de búsqueda.
- Volume: Debe de contener el numero de búsquedas de cada termino.
- Clicks: Estos datos no los utilizo en el proceso, solo a la hora de agrupar se calcula la media para cada grupo, por lo que puedes dejarlo vacío.
- Difficulty: Estos datos no los utilizo en el proceso, solo a la hora de agrupar se calcula la media para cada grupo, por lo que puedes dejarlo vacío.
- CPC: Estos datos no los utilizo en el proceso, solo a la hora de agrupar se calcula la media para cada grupo, por lo que puedes dejarlo vacío.
- CPS: Estos datos no los utilizo en el proceso, solo a la hora de agrupar se calcula la media para cada grupo, por lo que puedes dejarlo vacío.
- Return Rate: Estos datos no los utilizo en el proceso, solo a la hora de agrupar se calcula la media para cada grupo, por lo que puedes dejarlo vacío.
Todos los archivos csv que quieras procesar, debes de copiarlos en la carpeta “entrada”.
Para ejecutar el script solo tienes que ir a una consola de comandos , acceder hasta la ruta donde te has descargado el script y escribir:
python '.\Procesar KW Explorer Ahref.py'
Una vez ejecutado vas a ver como va procesando cada palabra clave y cada una de las tareas que te he explicado mas arriba.

Si quisieras desactivar alguna de las tareas puedes incluir los siguientes parametros:
- “-c False”: Para que NO elimine duplicados del listado.
- “-i False”: Para que no identifique las intenciones de búsqueda.
- “-l False”: Para que no identifique las ubicaciones.
Script 2: Listado generado con TPFusion
Otra de las formas en las que suelo buscar mis palabras clave, es mirando que esta posicionando la competencia con Ahref y descargando los listados de todos los competidores que me interese.
Después utilizo el programa TPFusion VIP que puedes encontrarlo dentro de TEAMPLATINO para unificar todos los listados y para que me calcule unas métricas que después me ayudaran a identificar las palabras clave con mas potencial.
De todas formas no te preocupes si no tienes acceso a la versión VIP del programa, Chuiso puso a disposición de su comunidad en Youtube una versión gratuita que te puede servir igualmente. Lo único que tendrás que usar el script adaptado para la versión gratuita.
Como en este caso utilizaremos el archivo csv procesado por TPFusion, no hay que tener en cuenta ningún requisito previo.
Para ejecutar el script solo tienes que ir a una consola de comandos , acceder hasta la ruta donde te has descargado el script y escribir:
python '.\Procesar KW TPFusion VIP.py' -f .\SALIDA_200322_223944.csv
El parámetro “-f” es para indicar el archivo que se va a procesar.
Una vez ejecutado vas a ver como va procesando cada palabra clave y cada una de las tareas que te he explicado mas arriba.

Si quisieras desactivar alguna de las tareas puedes incluir los siguientes parametros:
- “-i False”: Para que no identifique las intenciones de búsqueda.
- “-l False”: Para que no identifique las ubicaciones.
Conclusión
Una vez procesados cualquiera de los dos script, vas a obtener dos archivos:
- kw_procesado.csv: Este archivo contiene las mismas columnas que el archivo de entrada pero le han sido agregadas las nuevas columnas que se generan en el procesado.
- kw_agrupado.csv: Este archivo han sido agrupadas todas las palabras clave en grupos y solo contienen las columnas en las que se calculan las medias.
Tomando como ejemplo el archivo que yo he procesado para hacer este ejemplo, puedes ver como de 16.369 palabras clave en el archivo de entrada se ha reducido en mas de un 65% y en tan solo 9 minutos, aunque esta cifra puede variar en función de la capacidad de procesamiento de tu ordenador.
Llegados al final y si consideras que este contenido es útil para ti, solo me queda pedirte algo a cambio.
Comparte este articulo siempre que puedas, déjame un comentario o un enlace a este contenido si crees que puede complementar algún artículo relacionado que tengas.
Nos vemos en el siguiente artículo.
Buenos días , está genial y bien explicado, pero un vídeo tutoríal para los novatos como yo No estaría mal. La instalación la llevo mal.
Un saludo y gracias.
Hola Eva.
Es algo pendiente que tengo, pero si me cuesta escribir, mas me cuesta hablarle a una camara. Eso y que no tengo micro, pero prometo comprar uno en breve y hacer la explicación en vídeo.
Buenos días. Gran artículo y gran escript, sobre todo ingenioso. Tan ingenioso que no se como haces una cosa… ¿cómo averiguas la raíz léxica de la palabra? Como sabes que cantaron, cantaron, Cantabria,cantautor son todo palabras diferentes?
Gracias Sergio.
Para el tema de las raíces semánticas utilizo una librería de python para el procesamiento de lenguaje natural llamada NTLK.
Yo me he quedado parado en “acceder hasta la ruta donde te has descargado el script ” y no encuentro videotutoriales que lo expliquen paso a paso.
Hola Agustín
Estoy haciendo un videotutorial que adjuntare en breve, ya que sois muchos los que me estáis comentando que tenéis problemillas.
Muchas gracias por la aplicación es una pasado
me salta este error
Traceback (most recent call last):
File “Procesar KW Explorer Ahref.py”, line 10, in
import spacy
ModuleNotFoundError: No module named ‘spacy’
utilizo python3
Hola, me alegra que te guste.
Ese error te lo esta mostrando porque te falta la libreria “Spacy”.
Para poder instalarla ejecuta en la linea de comandos “pip install spacy”
Hola! gracias por tu tutorial, soy novato en esto de Phyton y quiero preguntar:
Cómo cargas los csv a la consola? o es sólo simplemente guardándolas en una carpeta que mencionaste? (entradas).
En los csv que generé, debo borrar las columnas extra que me genera como SERPS etc? o las dejo en blanco.
Todo esto porque me sale este error SyntaxError: invalid syntax y no puedo finalizar con el proceso.
Muchas gracias!
Hola Alexander
En la versión de Ahref basta con meter los archivos en formato csv en la carpeta “entradas”. El script leerá los archivos que tengan ese formato y los unirá en uno solo para luego procesarlo.
No, no tienes que borrar ninguna columna extra, solo asegurarte que estén las columnas que indico en el articulo y que este en formato UTF-8.
En la nueva versión que estoy haciendo todo esto lo verificara el script y hará un mejor control de los errores. El de ahora es funcional pero esta un poco cogido con pinzas.
Hola Jose Luis, lo primero de todo gracias por el script me ha ayudado mucho a la hora de “limpiar” los excel de ahrefs.
Tengo una duda, cómo podría utilizar el script con un listado de kw de otro programa (semrush, helium10…)
He intentado bajarme un csv de ahrefs y cambiarle las kw pero no cuela 😉
Hola, muy chulo el artículo pero la verdad no logro que me funcione,
—————————–
Traceback (most recent call last):
File “pro.py”, line 8, in
import pandas as pd
ModuleNotFoundError: No module named ‘pandas’
—————————–
Me tira ese error desde windows, alguna idea de qué es lo que falla?
saludos
Hola Dan.
Me alegro que te guste, aunque cuando lo veas funcionando seguro que te gusta mucho mas.
Ese error te ocurre porque te falta la librería “pandas”.
Para poder instalarla ejecuta en la linea de comandos “pip install pandas”
Espero haber resuelto tu problema. Cualquier cosa me dejas un comentario y seguro que lo echamos a andar.
Un saludo.
gracias!, tras instalar Panda, me ha vuelto a salir lo mismo con nltk, psacy y alguno más, así que he repetido el proceso,
pero el último me tira otro error:
————————–
C:\Users\Lenovo\Desktop\kw-phyton-general>pro.py
Traceback (most recent call last):
File “C:\Users\Lenovo\Desktop\kw-phyton-general\pro.py”, line 11, in
import es_core_news_sm
ModuleNotFoundError: No module named ‘es_core_news_sm’
C:\Users\Lenovo\Desktop\kw-phyton-general>pip install es_core_news_sm
ERROR: Could not find a version that satisfies the requirement es_core_news_sm (from versions: none)
ERROR: No matching distribution found for es_core_news_sm
————————-
Ya logré solventar el tema de es_core_news_sm y otros consecutivos,
ahora me he estancado por aqui:
https://imgur.com/qnpmDNv
Hola Jose Luís,
Lo primero muchas gracias por el aporte, me parece la caña. Y digo me “parece” porque no he sido capaz de hacerlo funcionar… xD
Me he asegurado de que el archivo esté en .csv (utf-8) y que tenga las columnas que comentas en el artículo. He ido instalando los módulos que me pedía y finalmente he conseguido que arranque.
Archivos cargados… OK
Duplicados eliminados… OK
Pero cuando va a empezar a calcular las raíces semánticas me salen un montón de líneas y al final:
KeyError: ‘Keyword’
¿Sabrías decirme qué puedo estar haciendo mal?
Un saludo
Ya lo he solucionado Jose Luis, era problema del archivo. Me han pasado uno y sí que lo lee sin problemas.
Mil gracias por el aporte porque funciona de lujo.
Saludos!
Después de mil vueltas logré hacerlo funcionar.
Mi gran problema fue con el encoding UTF-8.
Como no tengo Ahrefs, intenté hacerlo con un keyword research que tenía y por más que lo guardara en excel como “.csv UTF-8 delimitado por comas” no funcionaba. Entonces lo puse en el visual studio, reemplacé los tabs por comas, lo guardé como .csv, después ese archivo lo abrí en excel, lo volví a guardar como “.csv UTF-8 delimitado por comas” y recien ahí me funcionó.
Muy bueno! Gracias!!
Hola José Luis!
Primero de todo felicidades por tu script, la verdad que es de gran utilidad!
He estado trabajando con él últimamente y quería comentarte que he hecho un cambio en como se hace el matching con las ubicaciones e intenciones de búsqueda.
En vez de usar “.match” he hecho un cambio para usar el método “.contains”. Con match desafortunadamente solo me hacía la categorización correctamente si el término del matching se encontraba en las primeras posiciones de la palabra clave. En cambio, con “contains” me devuelve correctamente los índices de presencia del término independientemente de la posición en la que se encuentra.
Un saludo!
Genial artículo, muchas gracias por el aporte, en el script básico me aparece el error de que no encuentra el campo ‘Keyword’ y a priori el csv está correcto.
El mensaje es el siguiente, aparece el error en la línea 71 del código.
in get_loc
raise KeyError(key) from err
KeyError: ‘Keyword’
Un saludo